Почему вам не нужны уникальные тексты и чем их следует заменить
Традиционно считается, что уникальность текста на сайте — это хорошо. Копирайтеры заявляют стопроцентную уникальность как конкурентное преимущество, а заказчики напрямую просят обеспечить ту или иную цифру уникальности согласно тому или иному инструменту ее проверки. Win-win. Но почему уникальность контента вообще и текста в частности так важна? Да и важна ли? Что такое уникальность, если уж на то пошло?
И самое главное — стоит ли вам переплачивать за уникальность или можно обойтись вариантом попроще и подешевле? Ответ на последний вопрос вы скоро узнаете. Но давайте по порядку.
Что такое уникальность (с точки зрения человека)
На первый взгляд все понятно. Если некий контент не имеет аналогов, то он уникален. Однако уже здесь возникает проблема. Аналоги есть всегда. А если их нет, значит, скоро появятся. Преднамеренно или случайно. В виде плагиата, заимствования, отсылки, переосмысления, пародии, римейка, рерайта, репоста и еще многих других «ре-».
Уникальна ли композиция Quest Pistols «Я устал»?
А седьмой эпизод «Звездных войн»?

Поверьте, если бы определить уникальность контента было так просто, не ломалось бы столько копий вокруг авторских прав и не велись бы ожесточенные войны в судах по поводу, кто у кого украл.
Заботы правообладателей и юридические тонкости определения авторства нас с вами мало волнуют. Но даже если посмотреть с точки зрения конечного пользователя, то ситуация не становится сильно лучше. Кто автор фотографии с котом, которую вы вчера «лайкнули» в социальной сети? Вы взяли это фото на странице друга, тот еще где-то, и очевидно, что эта цепочка где-то имеет начало, а ваш друг — лишь очередное неуникальное звено в ней. Но вам-то какое дело, если конкретно вы конкретно эту фотку с котом увидели в первый раз? Для вас она уникальна.
Но давайте ближе к тексту. Лично мне нравится следующие два подхода к уникальности текста:
1. Текст уникален, если он предлагает читателю что-то новое.
Новое не конкретно для этого читателя (см. выше пример про котов), а новое по отношению к другим текстам. Что-то, чего в других текстах нет. Более глубокий анализ. Более подробное изложение. Иной взгляд на проблематику. Провокацию. Обсуждение. Мнение экспертов. Ретроспективу. Юмор.
А вот как это формулирует Matt Cutts:
2. Текст уникален, если он описывает уникальный продукт (услугу).
Если завтра объявят о выходе очередного iPhone, то какое-то время почти все тексты, посвященные этому событию, будут уникальны. Просто в силу того, что iPhone N до этого еще никогда не выходил.
Здесь нужно сделать две важных ремарки. Во-первых, речь идет об уникальности с точки зрения человека. Пока речь об этом. О поисковых системах ниже. Во-вторых, важным следствием вышеописанных критериев является тот факт, что для семантической уникальности текста совершенно не важна его фактическая уникальность.
Парадоксально, но факт:
Слова разные, а смысл тот же — это рерайт.
Слова те же, а смысл другой — это уникальный текст.
И ведь действительно, как бы ни изощрялись копирайтеры с SEO-шниками, а любой нормальный человек, включая вас и меня, на глаз легко определит, где текст оригинальный, а где компиляция или рерайт.
Чтобы не быть голословным приведу два примера.
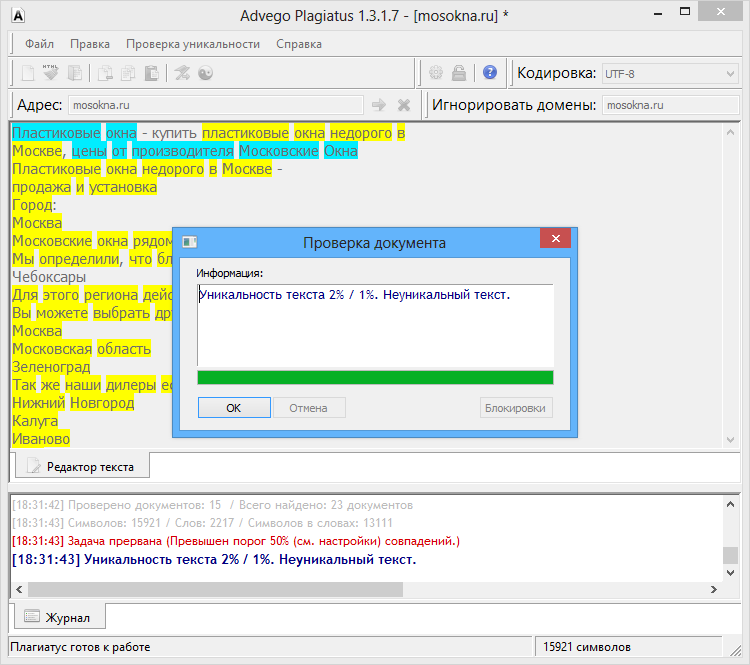
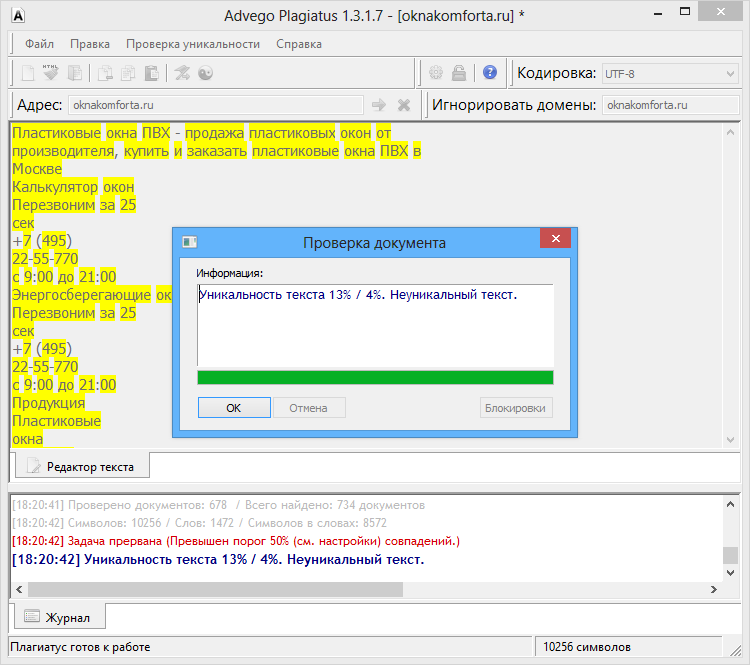
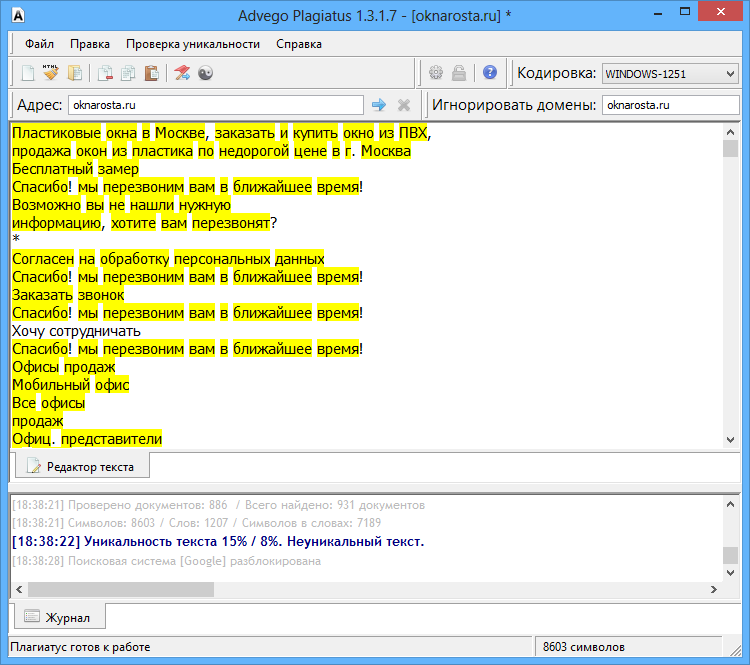
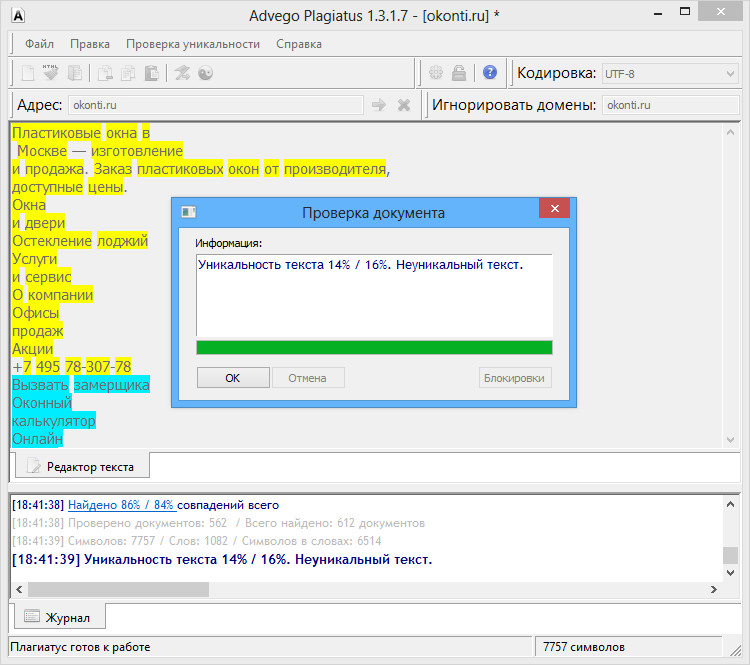
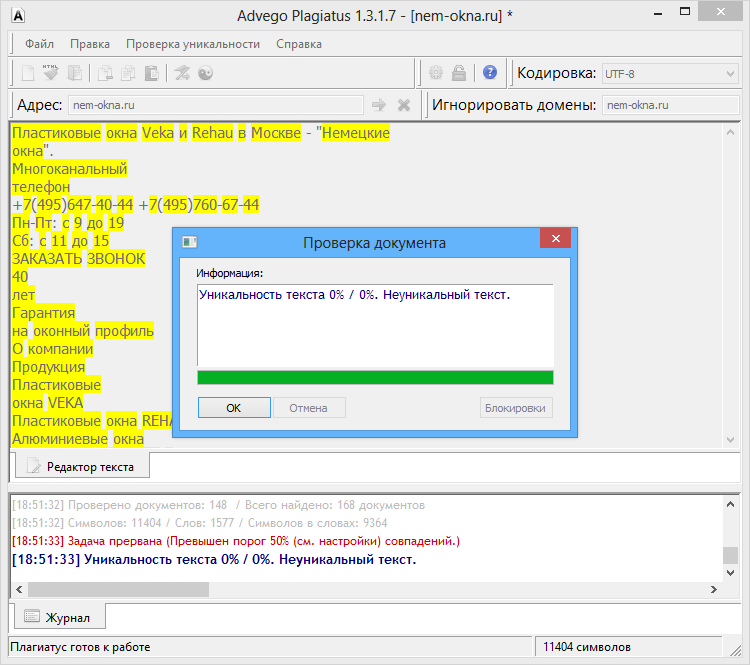
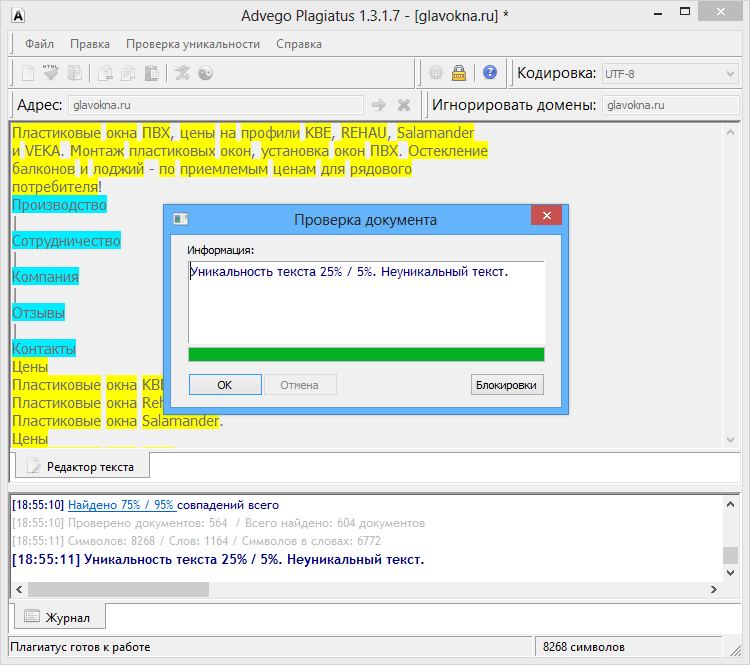
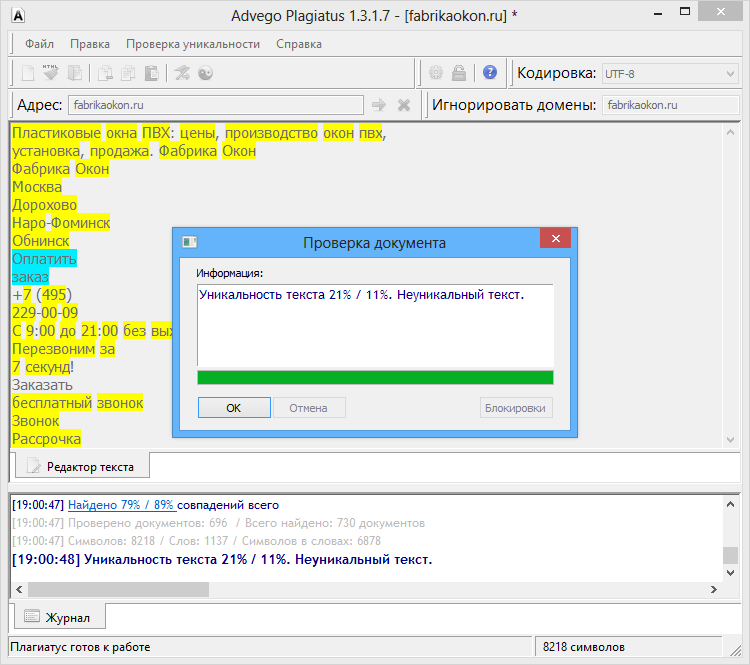
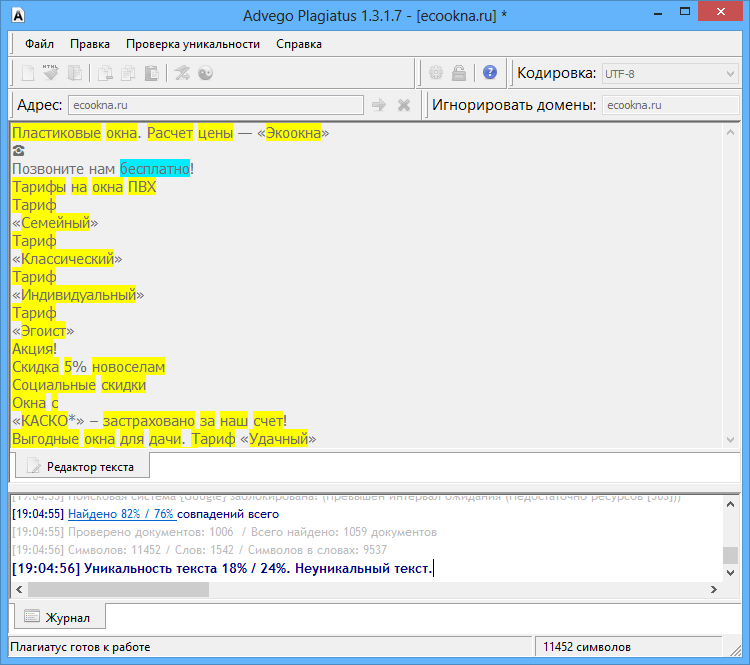
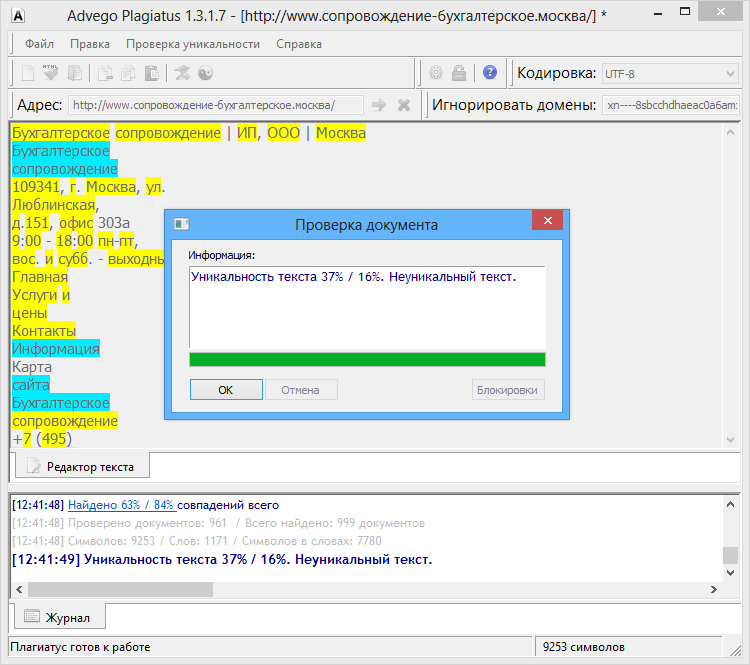
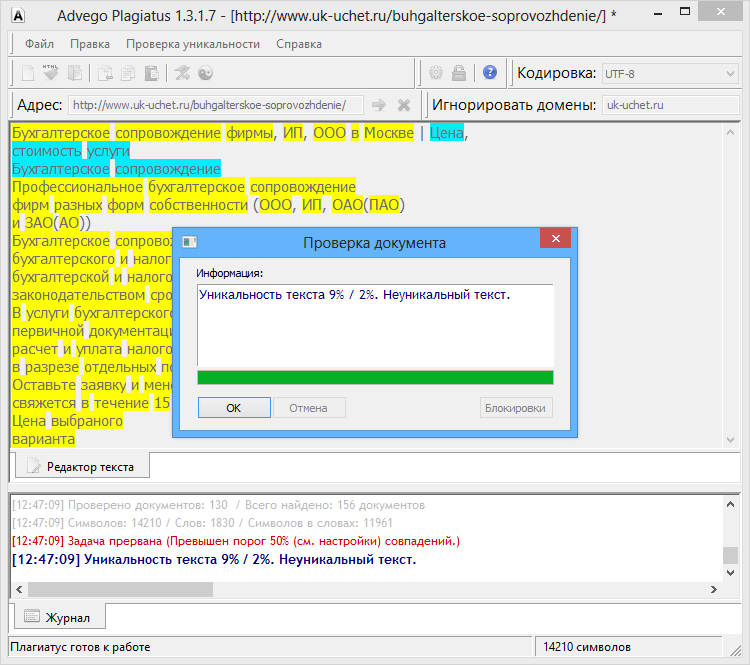
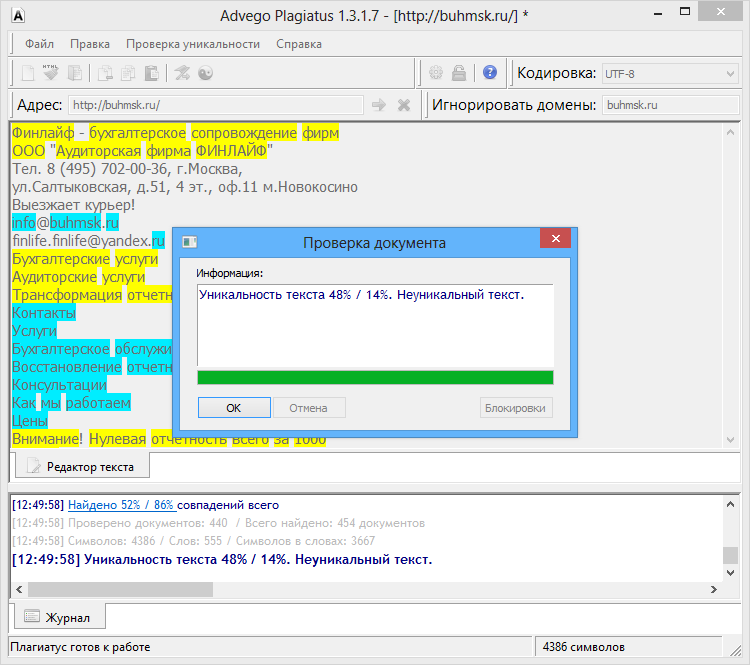
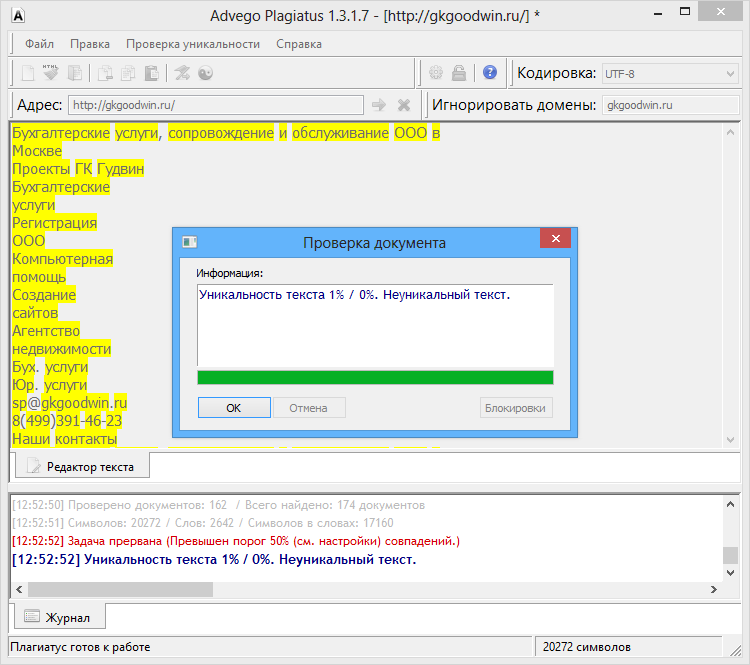
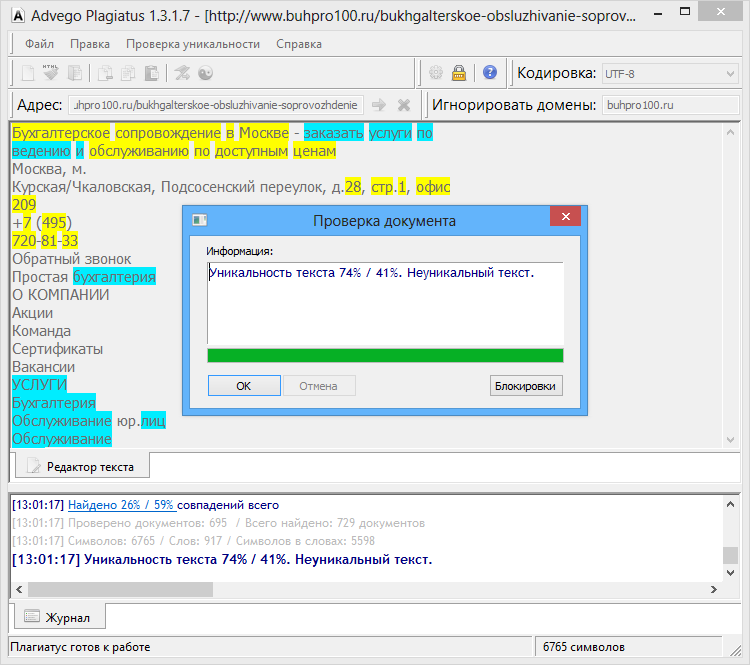
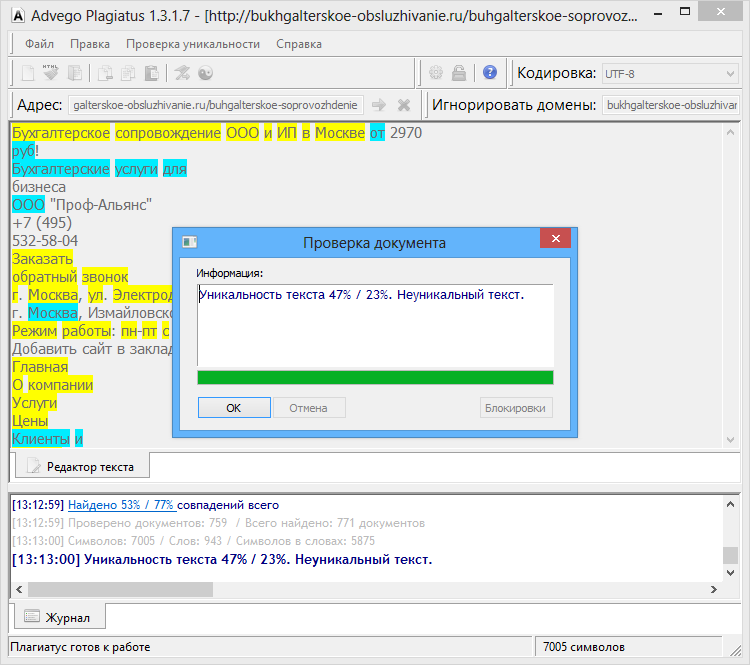
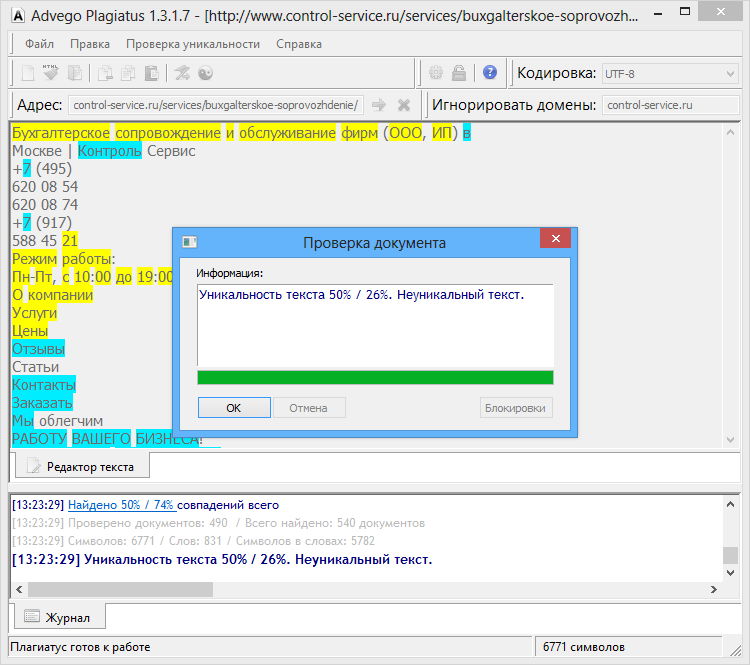
Пример 1
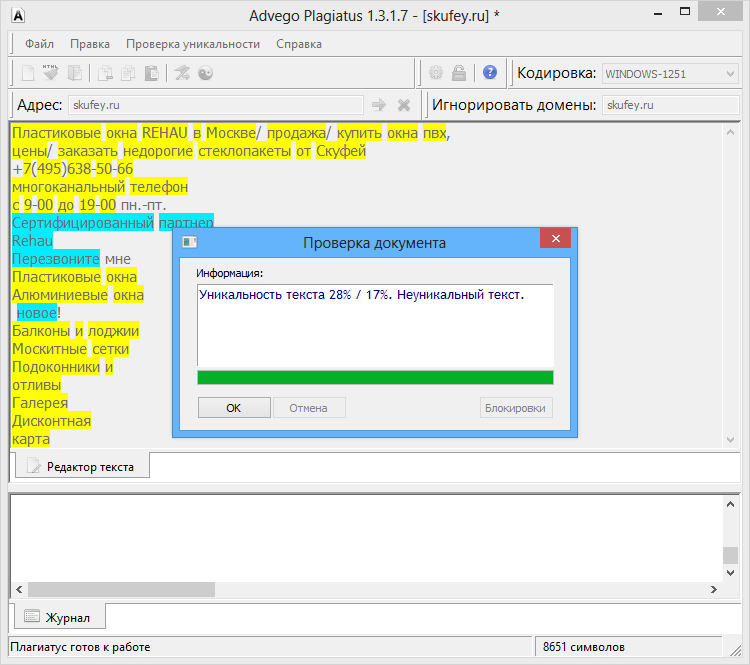
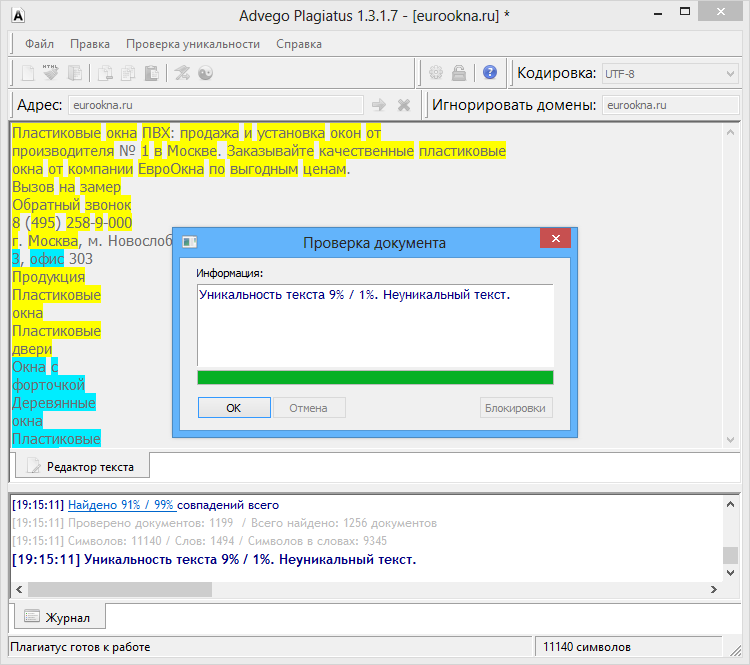
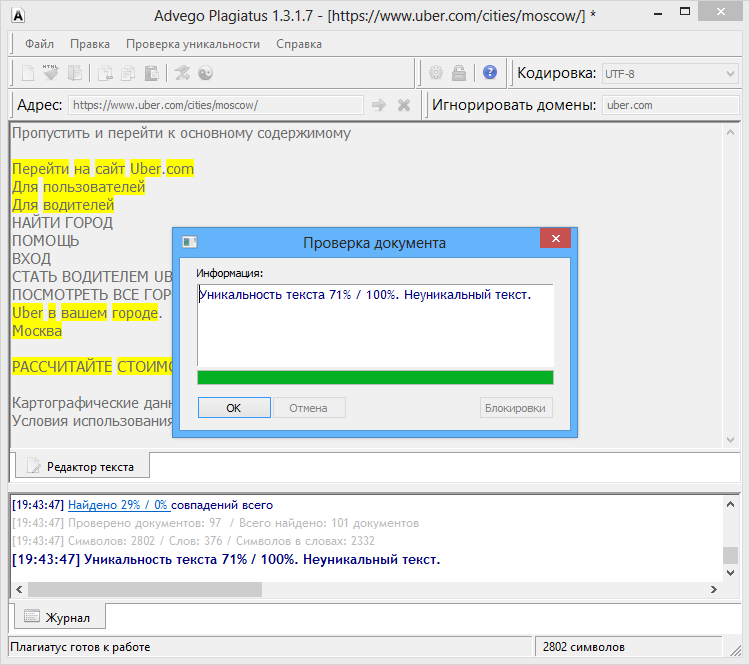
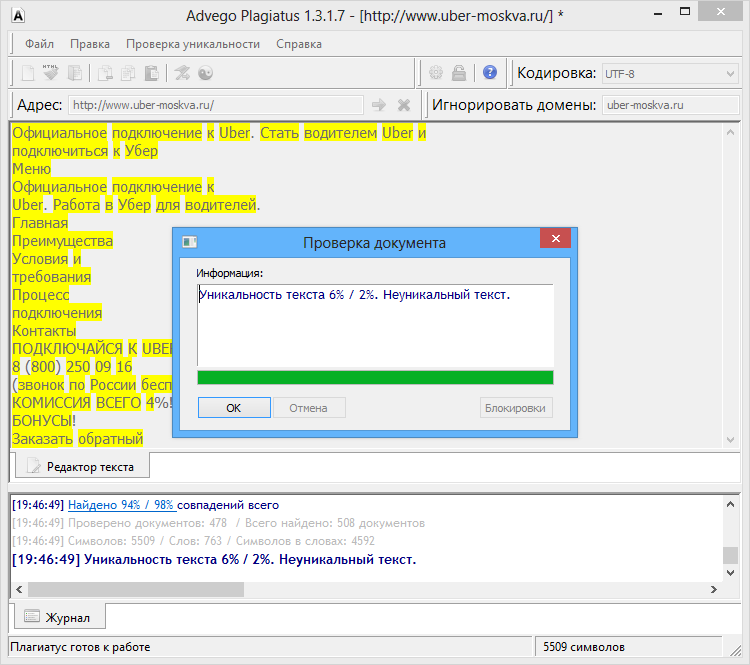
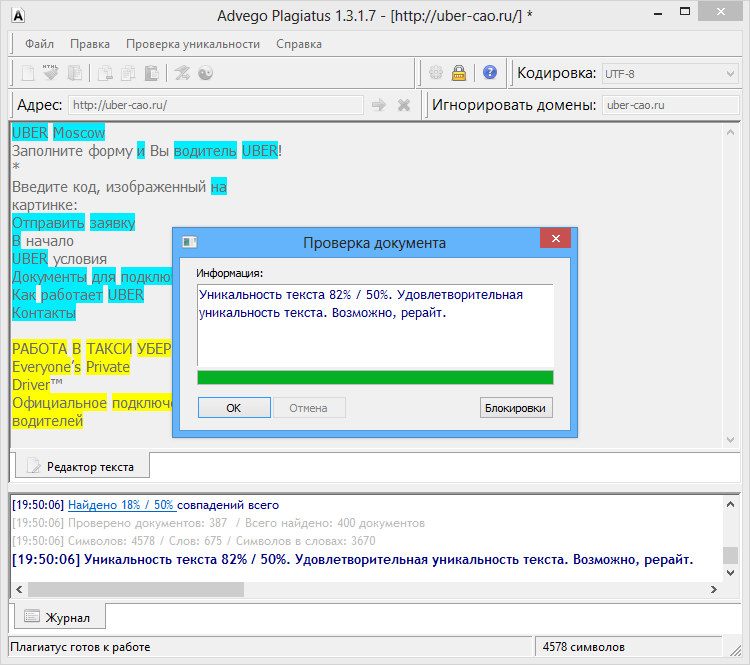
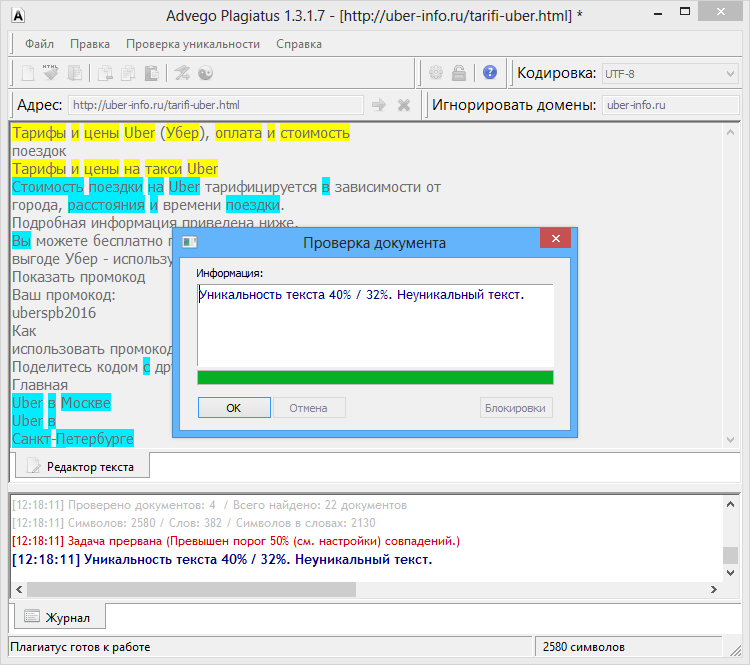
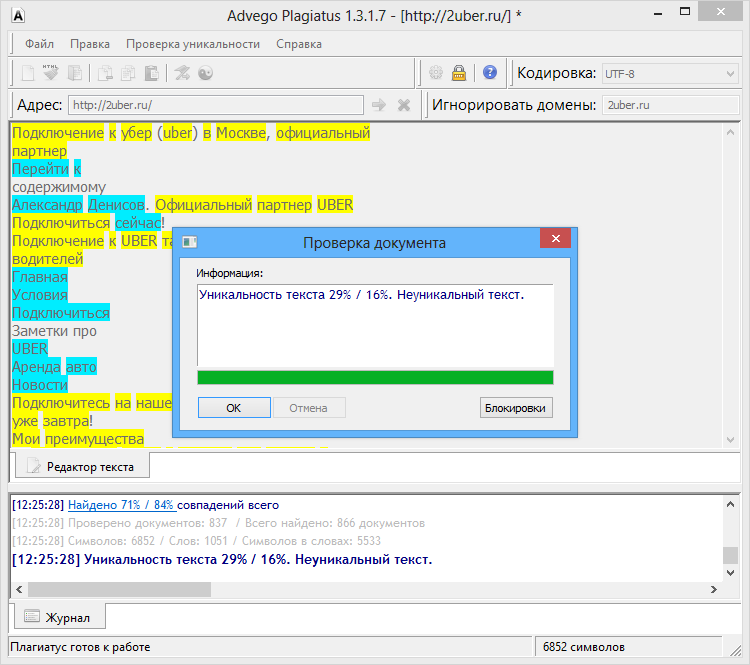
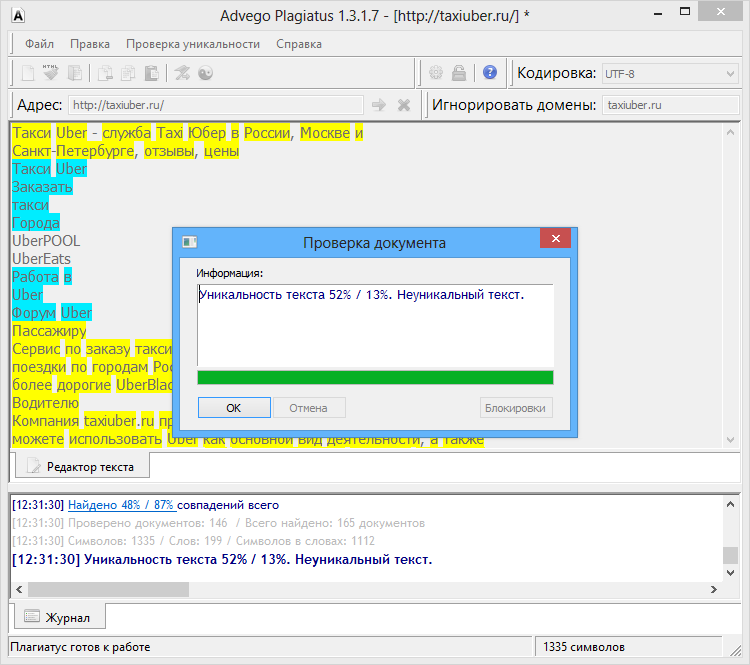
Возьмем два произвольных сайта из выдачи по некоторому произвольному запросу.


Здесь все очевидно и слепому. Абсолютно топорный рерайт. И, однако, при проверке фактической схожести текстов сервисы и программы показывают, что тексты лишь слегка похожи. Я проверил шестью разными способами:

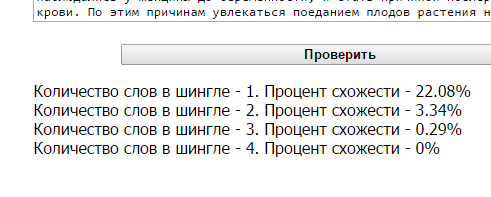
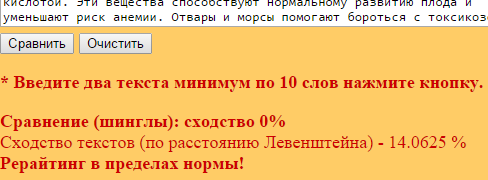

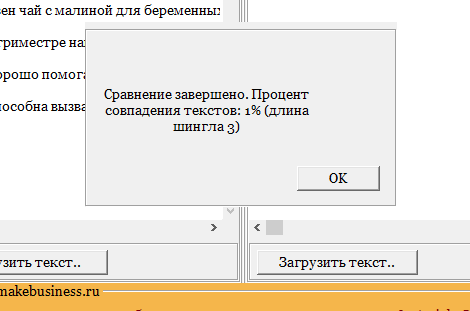
Пример 2
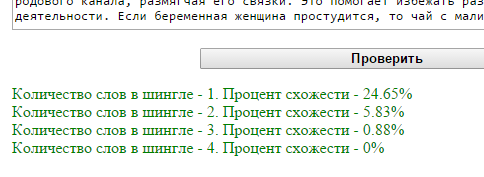
А теперь возьмем два текста, один из которых является прямым подражанием второму. Жанр называется «мэшап». Для чистоты эксперимента сравнивать будем английские оригиналы, а не переводы. Речь о “Pride and Prejudice” Джейн Остен, и ее мэшапной версии от Сета Грэм-Смита “Pride and Prejudice and Zombies”.
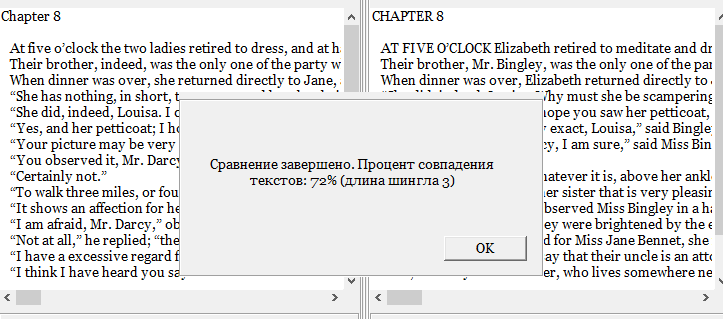

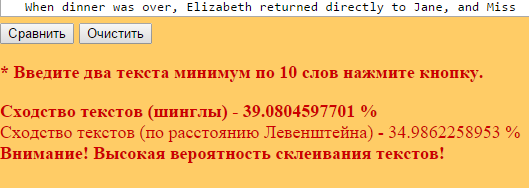

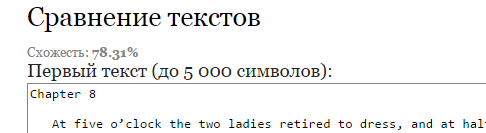
В этом случае только 5 сервисов. Потому что шестой, похоже, с текстами на английском языке работать не умеет. Результат, конечно, предсказуем. Вот только книги-то разные! Смысл книг разный!
Способов рерайта существует множество. Использовать синонимы. Поменять местами предложения или абзацы. Те, кто поприлежнее, переписывают текст своими словами (в школе это называлось «изложение», если помните). И все равно уши торчат. И все равно человек моментально понимает, что текст неоригинальный.
А вот формальные алгоритмы понимают это, как мы увидели выше, далеко не всегда.
И здесь мы плавно подходим к техническим нюансам определения уникальности. А заодно к вопросу о том, почему вообще при написании текстов на сайт с этой уникальностью приходиться заморачиваться.
")