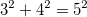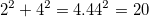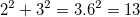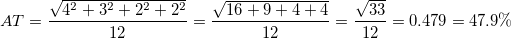Плотность тошноты на квадратный метр текста
Как с помощью наукообразных параметров копирайтеры обманывают клиентов (и самих себя)
Плотность ключевых слов, частотность, классическая тошнота, академическая тошнота, водность и даже, страшно подумать, индекс читабельности по Флешу. Утверждается, что все эти параметры учитывают поисковые системы. Приводятся «оптимальные» значения. Даются рекомендации. Кажется, чтобы написать текст, который априори понравился бы Яндексу, нужно быть копирайтером 80 уровня, не меньше. А если ты — не он, то придется найти такого и нанять. Так?

Не так. Ниже я покажу, что все перечисленные параметры не значат ровным счетом ничего. Ни-че-го. А также расскажу о том, что действительно имеет значение. Приступаем.
Плотность ключевых слов
Классическое определение плотности ключевых слов таково:
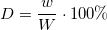
Здесь w — это количество вхождений ключевого слова в тексте. W — общее число слов в тексте.
Таким образом, если в тексте, например, 150 слов, а слово «копирайтер» встречается там 8 раз, то его плотность составляет:
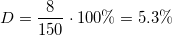
Методики подсчета общего числа слов в тексте и числа вхождений ключевых фраз могут отличаться. Кто-то учитывает предлоги, кто-то — нет. Где-то считаются только точные вхождения фраз, где-то — еще и «разбавленные» другими словами или употребленные в разных словоформах.
Уже само наличие расхождений в методике подсчета этого параметра опровергает наличие каких-либо точных значений плотности, которых следует придерживаться. Однако главная беда в другом.
Параметр плотности ключевых слов совершенно не влияет на ранжирование в поиске!
Доказательство — ниже, а пока забавная история.

В далеком 2004 году во время президентских выборов в США была запущена т.н. Google Bomb — массовая простановка ссылок на сайт Белого Дома с текстом «miserable failure» (жалкий неудачник). Флешмоб вылился в первое место страницы Буша-младшего в поиске Google по этому запросу. Надо ли говорить, что ни точного, ни «размытого» вхождения этой фразы в тексте страницы не было вовсе? История ныне слегка подзабытая, да и алгоритмы учета внешних ссылок уже много раз поменялись. Но суть осталась: формальные критерии вхождения слов в текст имеют далеко не первостепенное значение. И это еще мягко говоря.

Частотность
Определение частоты фразы или слова полностью совпадает с таковым для плотности. Т.е. берем число повторов слова или фразы и делим на общее число слов в тексте. Нюансы — в расчете общего числа слов (учитываем или не учитываем стоп-слова) и в способе выявления фраз.
Как следствие, влияние частотности ключевых слов на позицию в поисковой выдаче близко к нулю. Рассматривать этот параметр отдельно нет никакого смысла.
Тошнота текста
А вот здесь уже интереснее. И ведь термин-то какой — тошнота. Так и хочется, чтобы он был поменьше, правильно? Однако анализ показывает другое. Впрочем, обо всем по порядку. Итак, что же такое тошнота.
Честно говоря, о самом термине я впервые узнал примерно за две недели до того, как начал работать над этой статьей. Выяснилось следующее. Во-первых, существует два вида тошноты — классическая и академическая (sic!). Оба параметра призваны характеризовать переспамленность текста ключевыми словами. Во-вторых, проверка текста на тошноту довольно популярна в копирайтерской среде, хотя отношение к ней неоднозначное. Как же считается тошнота? Давайте узнаем.





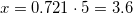 . Пока непонятно. Нужны еще данные.
. Пока непонятно. Нужны еще данные.

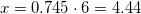

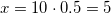 . А теперь поставим все три цифры рядышком и поглядим: 3, 4, 5. Ничего не напоминает? Подсказываю: число 5, по идее, мы получаем из первых двух.
. А теперь поставим все три цифры рядышком и поглядим: 3, 4, 5. Ничего не напоминает? Подсказываю: число 5, по идее, мы получаем из первых двух.